Picture this – you’re an aspiring teacher and you’ve been working hard on your application form. You’re busy, but organised and you want your application to be the best it can be.
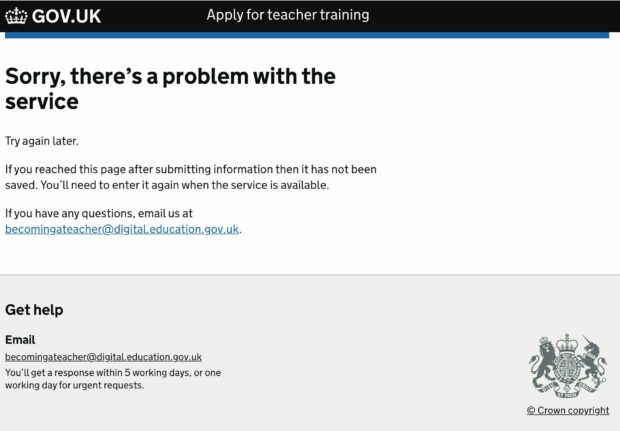
You set aside an evening to get it finished. You sign in to your application and you read “Sorry, there’s a problem with the service”.
You keep checking the site and when it eventually comes back online it’s too late, the evening has disappeared and you’re now forced to rush your application.
So, what happened? This message means there's been an incident behind the scenes, and the team hasn't been able to get the service back up and running in time.
This isn’t acceptable. As the owners of it, we have a duty to provide a reliable service and that includes how we manage incidents. So we’ve recently improved how we do this by building our very own Slack bot to manage incidents.
Handling incidents can be a challenge
As a developer, the old incident process caused a lot of pain. The instructions lived inside a Google Doc, but it frequently went out of date. So those not familiar with the process would often be unsure who to contact or how to assess the level of severity.
We spent longer working out what to do than dealing with the incident, and when we did finally trigger ‘the process’, it was just a Slack thread and a video call.
We wanted to improve this, so we could respond more effectively and provide our users with a better experience. We knew the process needed to:
- be easy and accessible, so everyone in the team would feel confident about raising an incident
- be automated and always follow a consistent set of actions
- produce better incident documentation
Creating a Slack bot
We wanted the process to remain in Slack and we considered using a pre-built app from the Slack Marketplace, but as developers we decided to build the bot ourselves. That way we could have something that completely met our needs and would be ours to customise and develop further.
As part of our development process we follow certain principles–we like our code to be well tested, open source and well-documented. It was important to us that we applied these principles to building the bot too.
We were keen to build the bot in C# or Ruby, our main programming languages. We found a great Slack-Ruby community on GitHub, which inspired us.
Bringing it to life
Now, when a developer notices something is wrong with the service, what do they do? Dig out that old Google Doc? Not any more. This is our new process.
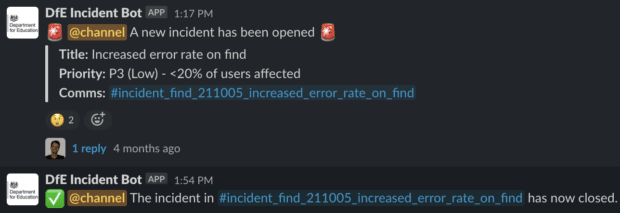
To trigger the incident bot you enter a single Slack command: /incident. (A window appears asking for information.)
You enter the required fields and the bot instantly creates a series of actions, which are:
- creating a brand new Slack channel for the incident
- inviting the incident leads to that channel
- setting the channel topic, with information such as a summary of the incident and severity level
- tagging useful documentation to the incident channel, so it’s easy to find
Once the incident has been resolved you simply issue another Slack command: /closeincident
It then alerts everyone, letting them know it’s now closed allowing the team to focus on the post-mortem.
What’s next
We do what we can to keep incidents to a minimum. So far we’ve only used our bot a few times. But when they occur, we’re clear about what we need to do.
Developers in other teams have welcomed our bot–it’s improved the process for all of us. We want to encourage more DfE service teams to use it. And we’re keen to get feedback so we can develop the bot to better meet user needs.
We’re always open to contributions and ideas. Here’s the bot’s source code on GitHub.
Or, if you’d rather work on it here in DfE, we’re hiring.
Recent Comments